













Merhabalar.
Bu yazımda MongoDB Compass ile bir database nasıl oluşturulur bunu göstermeye çalışacağım.
Öncelikle MongoDB Compass uygulamasını çalıştıralım.
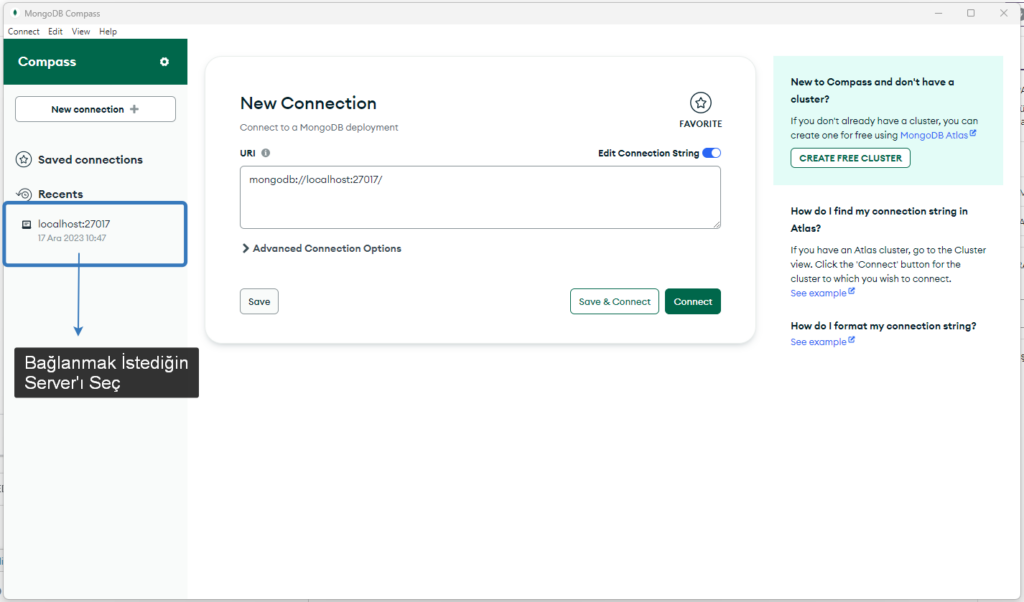
1 Server Seçimi
İlk açıldığında hangi Server’a bağlanacağınızı belirlemeniz gerekir. Aşağıdaki gibi seçelim.
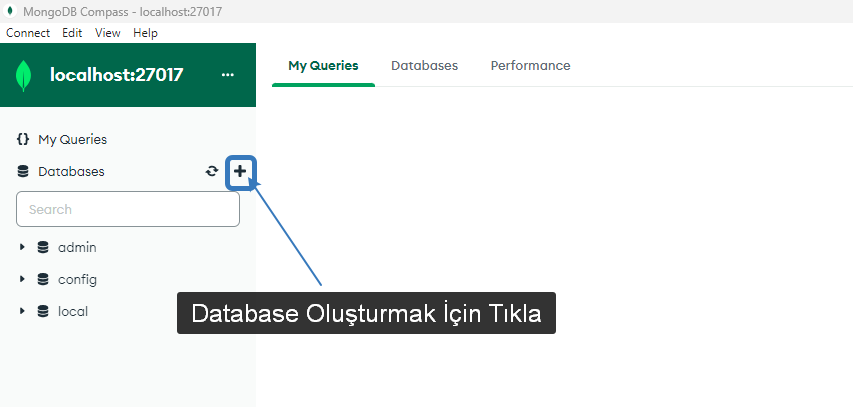
2 Database Oluşturma
Aşağıdaki + butonuna tıklayarak işlemi başlatalım.
Bir database mutlaka bir koleksiyon içermelidir. O yüzden ilk oluşturma sırasında bir Collection oluşturması da bekleniyor. Burada gerekli işlemleri yapıp Create Database diyoruz.
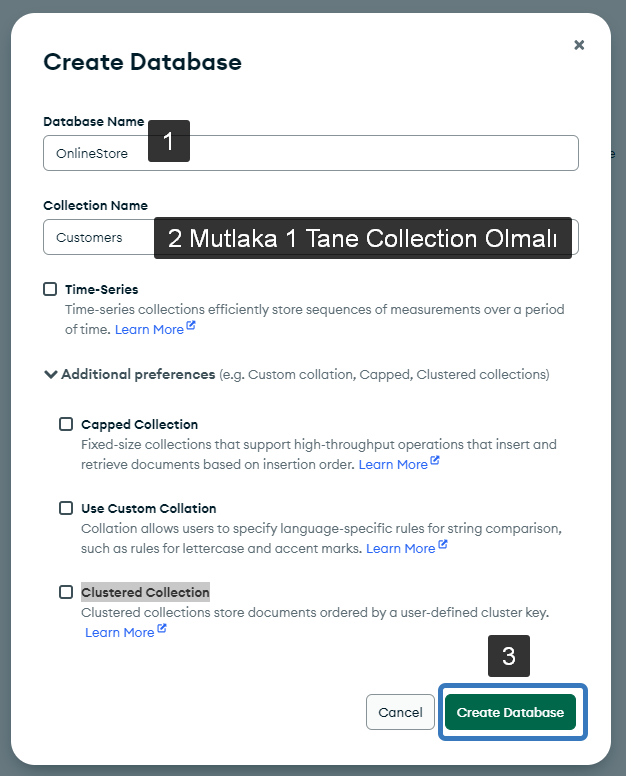
Bu adımda Additional olarak verilen özellikler var. Bunların ne işe yaradığına aşağıda değiniyor olacağım. İlginizi çekiyorsa okumadan geçmeyiniz.
3 Database Oluştu
Şu anda içinde hiçbir Document olmayan, Customers isimli Collection ile bir database oluştu.
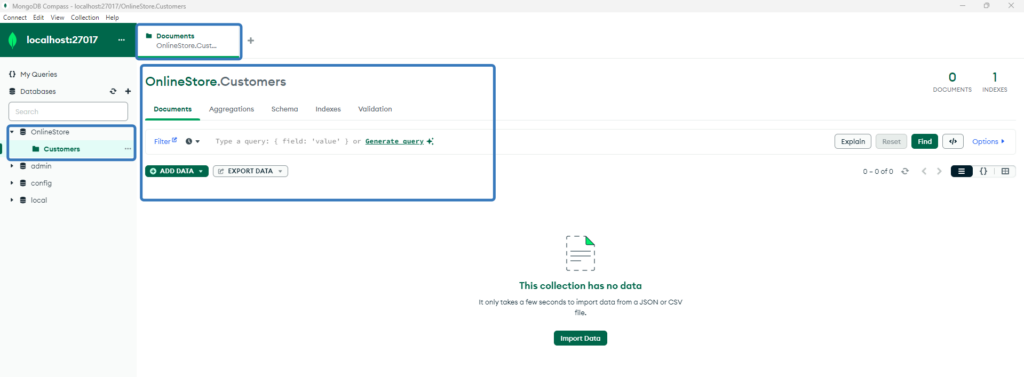
Compass üzerinde database oluşturmak bu kadar kolaydı.
4 Detay Okumalar İçin
Capped Collection
Capped Collection, MongoDB’de özel bir tür koleksiyondur. Bu tür koleksiyonlar, belirli bir boyutta ve belirli bir sıra ile belirli bir sayıda belgeyi saklamak üzere tasarlanmıştır. Capped Collection’lar, genellikle sıralı veri kaydı ve takip işlemleri için kullanılır.
Capped Collection’ların özellikleri şunlardır:
- Boyut Sınırlaması: Capped Collection’lar, belirli bir maksimum boyuta sahiptir. Bu boyut, koleksiyon oluşturulurken belirlenen bir parametredir. Yeni belgeler eklenirken, eski belgeler otomatik olarak yer açmak için silinebilir.
- Sıralama: Capped Collection’lar, belgelerin eklenme sırasını korur. İlk eklenen belge her zaman koleksiyonun başında bulunur ve son eklenen belge koleksiyonun sonunda bulunur.
- Yeniden Kullanım: Boyut sınırlamasına ulaşıldığında, koleksiyonun başından itibaren tekrar kullanılmaya başlar. Eski belgeler silinir ve yeni belgeler eski belgelerin üzerine eklenir.
Capped Collection’lar, sıralı veri tutma ihtiyacı olan senaryolarda, örneğin loglama veya geçmiş veri izleme gibi durumlarda kullanışlıdır. Boyut sınırlaması ve otomatik veri temizleme özellikleri sayesinde bu tür koleksiyonlar, belirli bir veri saklama politikasına uygun olarak tasarlanmıştır.
Use Custom Collation
MongoDB’de “use custom collation” (özel sıralama kullan) ifadesi, koleksiyonlardaki verilerin sıralanma ve karşılaştırılma yöntemlerini özelleştirmek için kullanılan bir özelliktir. Collation, karakter dizilerinin (string) sıralanma düzenini ve karşılaştırma kurallarını belirler. Özel bir sıralama belirleyerek, örneğin büyük/küçük harf duyarlılığı veya özel karakterlerin sıralama düzeni gibi özellikleri özelleştirebilirsin.
Bu özellik, MongoDB 3.4 ve sonraki sürümlerde desteklenmektedir. Koleksiyon oluştururken veya sorguları yapılandırırken belirli bir collation kullanmak için kullanılabilir.
Örneğin, bir koleksiyon oluştururken custom collation kullanma örneği:
db.createCollection("myCollection", {
collation: {
locale: "en_US",
caseLevel: true,
caseFirst: "lower",
strength: 2,
numericOrdering: true,
alternate: "shifted"
}
})
Bu örnekte, “myCollection” adında bir koleksiyon oluşturuluyor ve collation ayarlarıyla sıralama düzeni belirleniyor. Bu ayarlar, özellikle büyük/küçük harf duyarlılığı, sayısal sıralama, özel karakter sıralama düzeni gibi özellikleri kontrol etmeye olanak tanır.
Custom collation kullanımı, özellikle dil ve kültür özelliklerine bağlı olarak farklı sıralama kuralları gereken çok dilli uygulamalarda faydalı olabilir.
Clustered Collection
MongoDB’de kümelemiş bir koleksiyon, veri indeksleme ve erişim hızını optimize etmek için tasarlanmış özel bir koleksiyon tipidir. Verileri belirli bir sıraya göre fiziksel olarak saklar ve indeksleri de bu sıraya göre oluşturur. Bu sayede, sorgulamalar verilerin sıralanmış olması sayesinde daha hızlı gerçekleştirilir.
Kümelelenmiş koleksiyonların faydaları:
- Hızlı sorgulamalar: Sorguladığınız alan, koleksiyonun kümelenme sırasına dahilse, sorgu işlemi çok daha hızlı olacaktır. Örneğin, bir müşteri listesinde müşterileri soyadlarına göre sıraladıysanız ve soyadlarına göre filtre yapmak istiyorsanız, indeksler sayesinde veriyi taramak yerine doğrudan ilgili bölüme atlayabilir.
- Yüksek performans: Kümelemiş koleksiyonlar, özellikle büyük veri kümeleriyle çalışırken performansı önemli ölçüde artırabilir.
- Sıralı verilerin yönetimi: Sıralı verilerle çalışıyorsanız, kümelemiş koleksiyonlar doğal bir sıralama sunar ve ek sıralama işlemlerine gerek kalmaz.
Kümelelenmiş koleksiyonların dezavantajları:
- Esneklik azalabilir: Kümeleme sırasına göre olmayan alanlara göre sorgulamalar daha yavaş olabilir.
- Veri ekleme/silme performansı etkilenebilir: Veri ekleme ve silme işlemleri de sıralı yapıldığından, rastgele ekleme/silme işlemleri kadar hızlı olmayabilir.
- Yönetim karmaşıklığı: Kümelemeyi doğru şekilde seçmek ve yönetmek ek çaba gerektirebilir.
Kısaca, kümelemiş koleksiyonlar, belirli kullanım senaryolarında sorgu performansını optimize etmek için harika bir araçtır. Ancak, esneklik ve veri yönetimi üzerindeki etkilerini de göz önünde bulundurmak önemlidir.
Bir sonraki yazımda görüşmek üzere.